Face Recognition
- what is face recognition
- one hot learning
- siamese network
- triplet loss
- face verification and binary classification
1. what is face recognition
- face verification
- 이 사람의 얼굴과 신원이 일치하는지 확인하는 1:1문제
- 얼굴 사진을 input으로 받아, 이 사람의 사진과 이 사람의 ID가 일치하는지 여부를 output으로 반환
- face recognition
- 이 사람이 그룹 중 한 명인지 확인하는 1:K 문제
- 얼굴 사진을 input으로 받아, 이 사람이 group 중 한 명에 속하는지 여부를 output으로 반환
- face verification보다 어려운 문제이다.
2. one hot learning
face recognition 문제를 일반적인 model 방식으로 학습해도 괜찮은가?
일반적인 model(input-CNN-output)으로 학습을 진행하면 group에 한 명의 멤버가 추가된다면 모델을 재학습 해야한다.
왜냐하면 output node의 개수가 1개 증가해야 하기 때문이다.
게다가 한 사람에 대한 사진이 제한적이기 때문에 이 모델을 학습하는 것도 결코 쉬운 문제가 아니다.
이것은 좋은 방법이 아닌 것으로 보인다.
그렇다면 어떻게 학습을 진행해야 좋은가?
similarity function을 학습하는 것이다.
d(image_1, image_2) = degree of difference between images인 함수 d를 학습하여
d(img1, img2)의 결과가 임계값 이상이면 동일한 사람으로, 임계값 미만이면 다른 사람으로 판별하도록 하는 것이다
3. siamese network
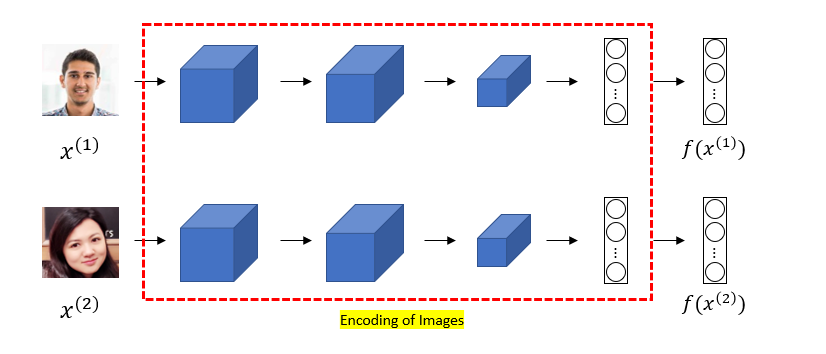
face recognition을 위해 모델을 학습하는데,
$$ \begin{cases}minimize ||f(x^{(i)})-f(x^{(j)})|| & x^{(i)} = x^{(j)}\\ maximize ||f(x^{(i)})-f(x^{(j)})|| & x^{(i)} \neq x^{(j)}\end{cases} $$
두 이미지 속 인물이 동일 인물이라면 모델 통해 encoding된 벡터 사이의 거리가 줄어들도록,
두 이미지 속 인물이 다른 인물이라면 모델 통해 encoding된 벡터 사이의 거리가 커지도록 학습하는 것이다.
4. triplet loss
위에서 이미지 속 인물이 동일 인물이라면 encoding vector사이의 거리가 줄어들도록,
다른 인물이라면 encoding vector 사이의 거리가 커지도록 학습을 한다고 했는데,
그렇다면 어떤 loss를 사용해서 모델을 학습해야 하는가?
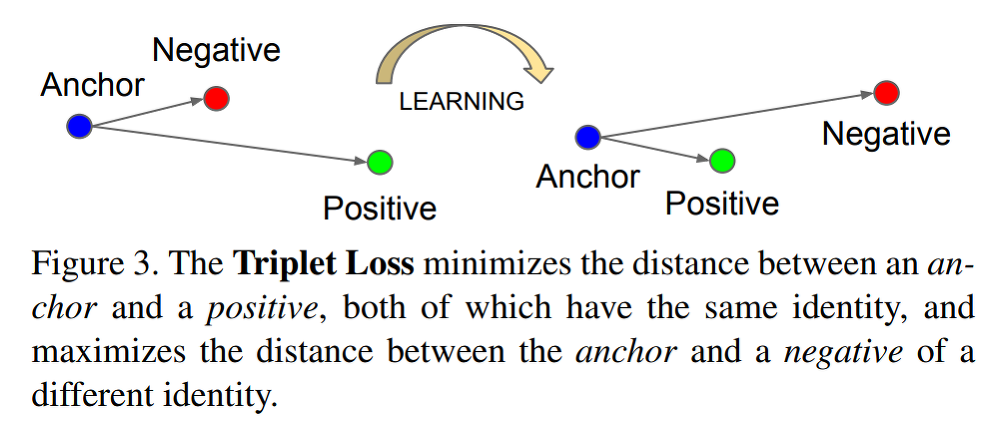
바로 Triplet Loss를 사용하는 것이다.
여기서 Anchor와 Positive는 동일 인물을 찍은 사진이고, negative는 다른 인물을 찍은 사진이다.
Anchor를 A, Positive를 P, Negative를 N이라고 표시했을 때 triplet loss는 다음과 같이 정의된다.
$$ L(A, P, N) = max(||f(A)-f(P)||^2 - ||f(A)-f(N)||^2 + \alpha, 0) $$
여기서 alpha를 사용한 이유는 무엇인가?
첫 번째, ||f(A)-f(P)||^2, ||f(A)-f(N)||^2 사이를 일정 거리(alpha)보다 커지도록 학습하기 위한 목적
두 번째, f(A), f(P), f(N) 모두 유사하게 나와 ||f(A)-f(P)||^2 > ||f(A)-f(N)||^2 조건을 만족하는 상황을 회피하기 목적도 있다.
즉, 이미지에 대해 다른 encoding vector가 나올 수 있도록 하기 위한 제약조건이다.
여기서 max(||f(A)-f(P)||^2 - ||f(A)-f(N)||^2 + alpha, 0)를 사용한 이유는 무엇인가?
||f(A)-f(P)||^2 + alpha가 ||f(A)-f(N)||^2보다 작다면 음수가 나오기 때문에 loss의 최솟값을 0으로 제한하기 위함이다.
일반적으로 ||f(A)-f(P)||^2 + alpha <= ||f(A)-f(N)||^2 를 만족하기는 쉽다.
이러한 경우 loss가 0이 되기 때문에 parameter가 데이터로부터 무엇인가를 배울 수 없게 된다.
따라서 ||f(A)-f(P)||^2 + alpha > ||f(A)-f(N)||^2이 될 수 있는, 즉 모델이 헷갈리기 쉬운 (A, P, N) 쌍의 데이터를 고르는 것이 중요하다.
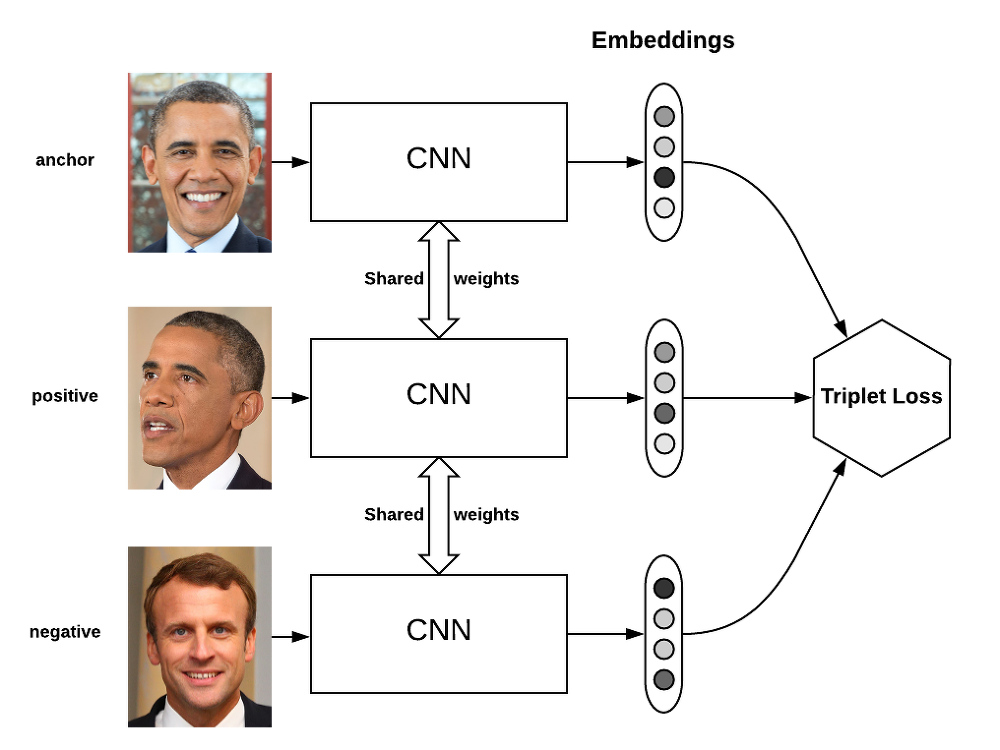
training data에서 triplet loss를 이용하여 CNN 모델을 학습한 후,
test time에서는 학습한 CNN 모델을 이용하여 이미지에 대한 encoding vector를 얻은 뒤,
DB에 존재하는 여러 명의 member들과의 encoding vector와 비교하여 group에 속하는지 여부를 리턴하게 된다.
5. face verification and binary classification
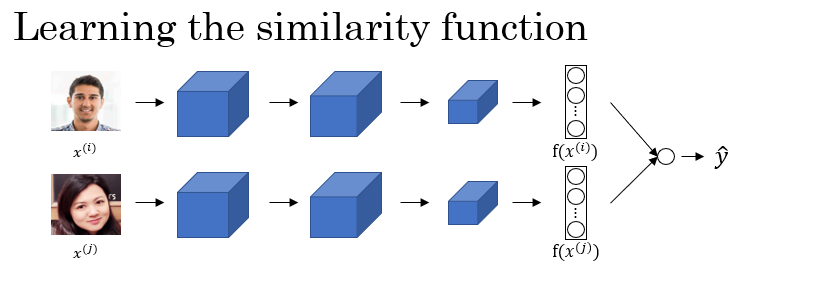
위와 방법이 아니라, binary classification으로도 face recognition 문제를 풀 수 있다.
두 사람의 이미지를 동일한 모델에 넣어 encoding vector를 구한 뒤,
두 벡터의 차이 벡터를 입력으로 하는 binary classification을 수행하여 두 이미지가 동일 인물인지 여부를 리턴하도록 한다.
$$ \hat y = \sigma(\sum_{k=1}^{V}w_k |f(x^{(i)})_k-f(x^{(j)})_k|+b) $$
- V : encoding vector의 길이
- f(x^(i))_k : i image의 encoding vector의 k번째 요소
'🙂 > Coursera_DL' 카테고리의 다른 글
| WEEK7 : convNet in 1D, 2D, 3D (0) | 2020.12.25 |
|---|---|
| WEEK7 : Neural Style Transfer (1) | 2020.12.25 |
| WEEK6 : Object Detection (2) (0) | 2020.12.23 |
| WEEK6 : Object Detection (1) (0) | 2020.12.23 |
| WEEK6 : convNet 사용에 도움이 될 지식 (0) | 2020.12.23 |