- Object Detection (1): hyoeun-log.tistory.com/entry/WEEK6-Object-Detection-1
- classification / object localization / object detection
- object localization
- landmark detection
- Object Detection (2): hyoeun-log.tistory.com/entry/WEEK6-Object-Detection-2
- sliding window detection
- convolutional implementation of sliding windows
- bounding box prediction
- IOU (intersection of union)
- non-max suppression
- anchor boxes
- YOLO
Ojbect Detection1
1. Object Localization, Object Detection
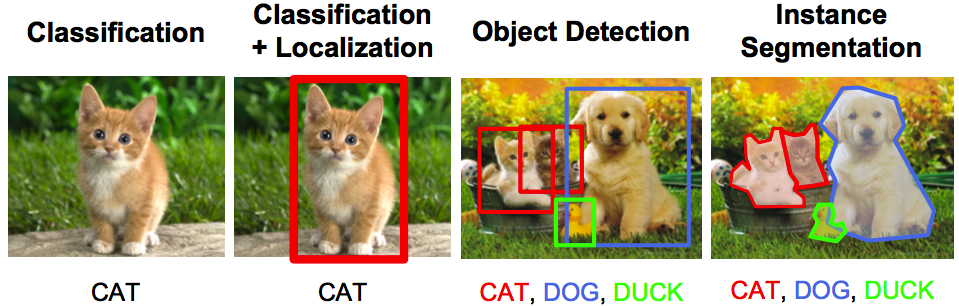
- Classification - 사진 속의 대상이 무엇인지 식별
- Classification + Localiation - 사진 속의 대상이 무엇인지 식별 + 그 대상의 위치를 bounding box로 표시
- Object Dectection - 사진 속 여러개의 대상을 식별해야 하고, 그 위치 또한 bounding box로 표기
- 차이점
- classification과 classification+localization은 하나의 객체를 다루고,
- object detection은 여러개의 객체를 다룬다.
2. Classification with localization
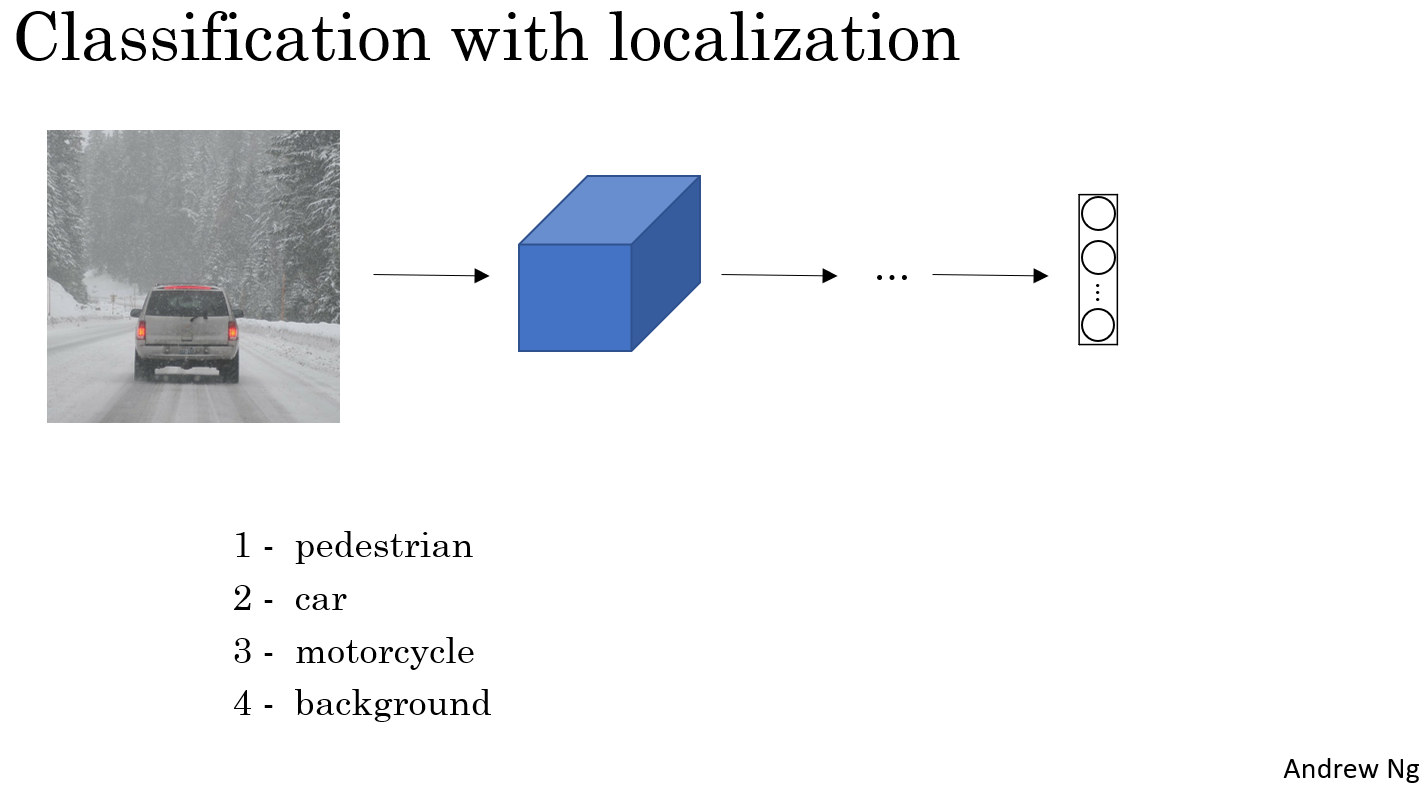
- 단순한 classification 문제였다면,
- [보행자, 자동차, 오토바이, 그 외]를 target으로 one-hot vector로 넣어주고,
- output node 역시 각각에 대응되는 정보를 의미했을 것이다.
- 하지만 이것은 classification + localization 문제이기 때문에
- [객체 존재 유무(y1), 보행자(y2), 자동차(y3), 오토바이(y4), bx, by, bh, bw] 를 정답으로 넣어준다.
- 여기서 bx, by는 bounding box의 중심점의 위치를 의미하고, bh와 bw는 각각 bounding box의 height와 width를 의미한다.
- classification + localization loss를 구할 때
- 객체 존재 유무가 0이라면 (=객체가 없다면) 실제 y1과 예측 y1만을 비교해 loss구하고,
- 객체 존재 유무가 1이라면 (=객체가 있다면) y1, y2, y3, y4, bx, by, bh, bw 이용해 loss를 구한다.
- 이 때 (bx, by, bh, bw)에는 MSE loss를 적용하고, (y1, y2, y3, y4)에는 cross-entropy loss를 적용하는 등
각각의 요소마다 다른 loss를 적용할 수 있다.
3. landmark detection


classification + localization과 유사하게 landmark detection도 학습할 수 있다.

64개의 landmark가 존재한다고 가정하면,
conv layer의 마지막에 64개의 randmark 위치를 예측하는 node를 추가해주는 것이다.
landmark detection에서 주의할 점은 각각의 landmark가 의미하는 것이 동일해야 한다는 것이다.
예를 들어 landmark1은 왼쪽 눈의 가장 왼쪽 가장자리를 의미한다, landmark2는 오른쪽 입꼬리를 의미한다 등등과 같이 말이다.
이렇게 모든 이미지에 대해 각각의 landmark가 상징하는 것이 동일해야 한다.
'🙂 > Coursera_DL' 카테고리의 다른 글
| WEEK7 : face recognition (0) | 2020.12.24 |
|---|---|
| WEEK6 : Object Detection (2) (0) | 2020.12.23 |
| WEEK6 : convNet 사용에 도움이 될 지식 (0) | 2020.12.23 |
| WEEK6 : Inception (googLeNet) (0) | 2020.12.23 |
| WEEK6 : ResNet (0) | 2020.12.23 |