weight initialization이 중요한 이유
- ⭐ exploding / vanishing gradient 문제를 막기 위해서 weight initialization도 신중하게 해주어야 한다.
- $$ dW^{[l]} = dZ^{[l]}A^{[l-1]^T} $$
- 이므로 weight matrix의 각 요소가 크다면 exploding gradient 문제를,
- weight matrix의 각 요소가 작다면 vanishing gradient 문제를 유발한다.
- ⭐ 입력 노드의 수가 많은 경우에는 weight를 더 작게 해주는 방식으로 초기화를 진행해준다.
- 입력 노드가 많은 경우 가중치가 조금만 커도 전체 계산된 z값이 크기 때문이다.
- z값이 크면 a값도 커지고, 따라서 gradient가 exploding된다.
영행렬로 가중치 초기화하는 방법의 문제점
- all zeros -> 모든 parameter가 동일한 값으로 update된다.
- neuron을 만드는 이유는 서로 다른 특징을 포착하기 위함인데, 이렇게 가중치 업데이트가 일어나면 여러개의 neuron을 만드는 이유, 층을 쌓는 이유가 사라지기 쉽다.
정규분포를 따르는 가중치 초기화 방법의 문제점
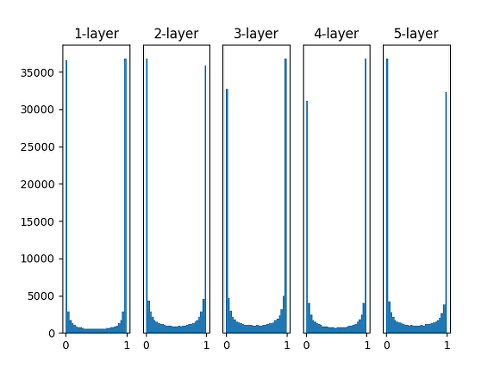
- 평균이 0, 표준편차가 1인 정규분포를 따르는 값으로 weight matrix를 초기화한 경우
- activation function으로 sigmoid 함수를 사용했을 때 그 결과가 0 또는 1로 치우치는 현상이 발생한다.
- sigmoid 함수는 0과 1근처에서 미분값이 0이기 때문에 vanishing gradient 문제로 이어진다 😢

- 평균이 0, 표준편차가 0.01인 정규분포를 따르는 값으로 weight matrix를 초기화한 경우
- activation function으로 sigmoid 함수를 사용했을 때, 그 결과는 0.5로 치우치는 현싱이 발생한다.
- sigmoid 함수는 0 부근에서 선형의 형태를 띄는데, 모든 출력이 0.5에 치우친다면 layer를 쌓는 의미가 사라진다.
- 즉 비선형패턴을 학습하지 못하는 문제가 발생한다.
Xavier Initialization
- 입력 노드의 개수에 기반하여 weight를 초기화한다.
- 입력 노드의 개수가 많아지면 분산이 작아지도록, 입력 노드의 개수가 적어지면 분산이 커지도록 해준다.
- W = np.random.randn(n_input, n_output)*sqrt(1/n_input)
He Initialization
- 활성화함수로 ReLU를 사용하는 경우, Xavier initialization 방법은 적절하지 않다. He initialization 방법이 적합!
- W = np.random.randn(n_input, n_output) * sqrt(2/n_input)
- Xavier initialization 방법보다 분산을 조금 더 크게 설정
- 가중치 행렬을 0으로 초기화하는 것은 절대 금지
- sigmoid, tanh 활성화함수를 사용하는 경우에는 Xavier initialization 방법을,
- ReLU 활성화함수를 사용하는 경우에는 He initialization 방법을 사용하라.